Agents IA en entreprise, guide du recrutement 2026 — 3/7 : IA Générative vs. IA Agentique
On parle d’« IA » comme si c’était une seule et même chose. Dans la même réunion, le même mot recouvre l’outil que votre équipe marketing utilise pour rédiger des posts et le système censé piloter demain un bout de votre supply chain. Ce sont deux objets différents, qui n’exigent ni les mêmes données, ni la même gouvernance, ni le même calendrier d’investissement. Tant qu’on les confond, on prend de mauvaises décisions sur les deux.
Posons-les proprement.
Série « Agents IA en entreprise », article 3/7. Par Florent Cattaneo, associé Uman Partners, en charge du management de transition Data & IA.
Le génératif et l’agentique : deux objets, pas un
L’IA générative, c’est un exosquelette. ChatGPT, Claude, Copilot : vous êtes dans la boucle, en permanence. Vous lui demandez quelque chose, il produit, vous gardez la main. Chaque sortie passe par votre validation. C’est une amplification de votre geste (vous écrivez plus vite, vous analysez plus vite, vous codez plus vite) mais c’est toujours votre geste. L’exosquelette ne marche pas tout seul. Quand vous vous arrêtez, il s’arrête.
L’IA agentique, c’est un robot. Vous lui confiez un périmètre, et il agit. Il enchaîne des étapes, prend des décisions intermédiaires, appelle des outils, sans vous repasser la main à chaque pas. Il travaille pendant que vous êtes en réunion, pendant la nuit, pendant que vous dormez. Ce n’est plus une extension de votre main : c’est quelque chose qui opère seul sur un bout de votre activité.
L’écart n’est pas une question de puissance du modèle. C’est une question de place de l’humain dans la boucle. Avec l’exosquelette, vous êtes le moteur. Avec le robot, vous êtes, au mieux, le superviseur.
Ce qui sépare vraiment les deux : l’horizon temporel
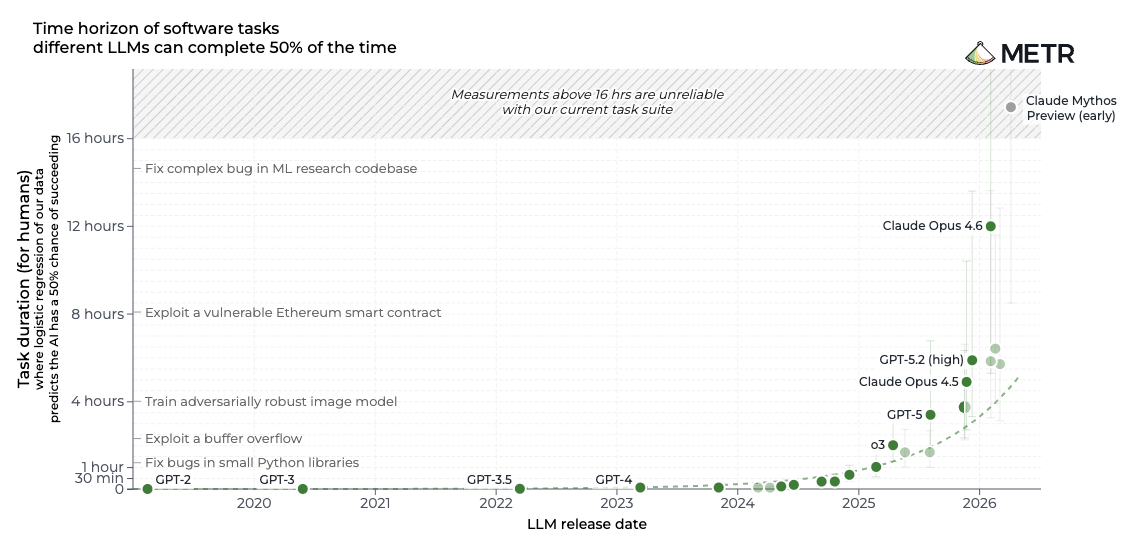
Le vrai marqueur de bascule, ce n’est ni la qualité des réponses ni la taille du modèle. C’est l’horizon temporel : combien de temps le système avance-t-il seul avant qu’un humain doive reprendre la main ?
Un outil génératif n’a, par construction, pas d’horizon. Vous validez chaque sortie ; l’horizon est nul, il se remet à zéro à chaque prompt. Un agent, lui, en a un, et on sait désormais le chiffrer. C’est ce que mesure METR, un laboratoire de recherche indépendant qui évalue les capacités réelles des systèmes d’IA frontière, avec la notion de task time horizon : la durée d’une tâche qu’un système réussit à mener seul. Retenez la notion pour l’instant ; on regardera la dynamique plus loin.
Le génératif, vous le connaissez déjà, même si vous ne le savez pas forcément.
Sécurisez le génératif, puis évacuez-le
Soyons clairs sur un point : le génératif n’est plus un pari. C’est prouvé, documenté, balisé. Ce n’est plus un sujet de stratégie, c’est d’abord un sujet de workplace.
Et sur ce terrain, vous n’avez pas le choix. Vos collaborateurs utilisent déjà l’IA, avec ou sans vous. Selon une étude HBR (Alfaro et al., 2026), environ 40 % des entreprises ont acheté des licences officielles, mais dans plus de 90 % d’entre elles, des collaborateurs utilisent déjà l’IA grand public. Le shadow IT est là. La seule question est de savoir si vous le canalisez ou si vous fermez les yeux. Canaliser, pas interdire : interdire ne fait que pousser les usages hors de votre vue et vers des zones dangereuses pour votre entreprise.
Chez Foodles, j’ai déployé avec mon équipe des outils génératifs en 2025. Nous avons fait gagner 15 000 heures de productivité annuelle en trois mois, non pas par un grand plan descendant, mais par des ambassadeurs internes qui ont diffusé les usages d’équipe en équipe. Même mécanique chez BBVA, l’un des plus grands groupes bancaires européens (~125 000 collaborateurs, présence dans 25 pays), qui est passé de 3 000 à 11 000 utilisateurs internes de l’IA générative en moins d’un an (HBR, Alfaro et al., 2026). La méthode qui marche est toujours la même : commencez petit, faites grandir par l’intérieur. Pas un déploiement, une contagion.
En environnement régulé (banque, assurance, santé, secteur public) c’est plus dur. Pas bloqué, plus dur. Les contraintes de confidentialité, de traçabilité et de conformité changent la donne. C’est exactement là qu’un de nos managers de transition qui l’a déjà vécu vous fait gagner six mois : il connaît les pièges, les architectures qui passent la conformité, les angles morts qui font capoter un déploiement.
Mais une fois cette étape sécurisée et diffusée, faites-en une routine, pas un chantier. Ne sautez pas l’étape du génératif, mais ne vous y attardez pas non plus. On sécurise, on diffuse, et on évacue le génératif de la liste des grands chantiers, pour concentrer l’énergie sur l’agentique. Parce que l’agentique, lui, arrive vite.
L’agentique arrive et progresse de façon exponentielle
Voici ce qui devrait retenir l’attention de tout dirigeant. La durée d’une tâche qu’un agent réussit seul, le task time horizon, double environ tous les 7 mois depuis 2019. Et le rythme accélère : environ tous les 4 mois depuis 2023, environ tous les 3 mois depuis 2024. Une sorte de loi de Moore de l’autonomie.
Un mot sur la mesure, parce qu’elle est inhabituelle. METR fait passer aux modèles une batterie de tâches calibrées en temps humain expert : des tâches qu’un développeur ou un chercheur senior réaliserait, chronomètre en main, en deux minutes, en une heure, en huit heures. Le task time horizon d’un modèle, c’est la durée d’une tâche humaine que ce modèle réussit la moitié du temps. C’est une jauge d’autonomie effective, pas un score de benchmark abstrait.
Concrètement : on est passé de quelques secondes (GPT-2) à environ cinq heures fin 2025 (Claude Opus 4.5), la pente continue de monter en 2026. Si la dynamique tient, la projection de METR situe les tâches d’un mois humain entier dans le viseur autour de 2027.
La machine est de plus en plus puissante. Mais paradoxalement on en voit encore assez peu souvent en production à grande échelle. Tout le monde est capable de montrer un POC, même souvent assez impressionnant, mais personne ou presque ne montre des systèmes qui fonctionnent à l’échelle d’un processus métier entier sur des grands volumes.
J’ai déjà vu ce film en tant que data scientist en 2019 chez Décathlon. On accumulait des dizaines de POC de machine learning. La capacité de développement de preuves de concept était énorme, et le passage en production était un mur. Industrialiser un modèle faisait peur. Aujourd’hui, entraîner et opérer un modèle en production n’est plus un sujet : c’est devenu une commodité d’ingénierie.
Le même schéma se rejoue avec l’agentique : beaucoup d’expérimentation, peu d’industrialisation. Le passage à l’échelle viendra, il vient toujours. La question n’est donc pas si, mais quand. Et le quand arrive vite, bien plus vite que les cycles d’investissement et de transformation que j’observe chez la plupart de nos clients.
J’ai l’opportunité, avec notre cabinet de management de transition fondé en 2025, de construire à partir d’une feuille blanche. J’ai reconstruit, seul, l’infrastructure logicielle complète d’un cabinet avec Claude Code. Pas (juste) pour m’amuser, mais parce que ça me permet d’intégrer des fonctionnalités d’IA que les éditeurs de solutions, même ceux qui font référence sur le marché, tardent trop à déployer. Je mesure, et parfois ça me donne le vertige, le potentiel de reconstruire de zéro n’importe quelle entreprise ou logiciel en mode agentic-first.
C’est précisément en mesurant ce potentiel que je vois apparaître l’écart d’exécution : la distance entre ce que la machine sait déjà faire et ce que l’organisation est capable d’absorber. Côté intention, près de trois entreprises sur quatre prévoient de déployer de l’agentique sous deux ans, mais seule une sur cinq dispose d’une gouvernance mature (Deloitte, State of AI in the Enterprise 2026). Du côté des dirigeants eux-mêmes, seuls 25 % anticipent des agents « coéquipiers autonomes » sous un à deux ans (McKinsey, The State of Organizations 2026). La capacité court devant ; l’organisation, elle, n’a pas commencé à courir. C’est cet écart que nous voyons, mission après mission, et c’est exactement le terrain du management de transition.
Faut-il vraiment faire le ménage de la data avant l’IA ?
Avant d’attaquer ce que l’agentique change dans votre organisation, il faut désamorcer un faux préalable que j’entends dans presque chaque comex où on parle d’IA : « d’abord on nettoie la data, ensuite on fait de l’IA ».
Cette phrase a été forgée pour la décennie 2015-2022, celle du ML supervisé, des dashboards exécutifs, des pipelines ETL. Sur ce périmètre, elle reste juste : on ne nourrit pas un modèle de pricing avec des données sales, et un COMEX ne pilote pas sur un référentiel ambigu. Mais pour l’agentique, elle ne tient plus, et pour quatre raisons.
Un, les LLM tolèrent un bruit que le ML classique ne tolérait pas. Un agent qui interroge un ERP via une couche d’outils gère les conventions de nommage hétérogènes, les champs commentaires bricolés, les héritages de migration. Ce qui aurait fait planter un pipeline ETL passe sans heurt : il lit en langage naturel, il raisonne, il pose des questions de clarification.
Deux, le dogme confond data et schéma. L’agent n’a pas besoin que dix ans d’historique soient nettoyés. Il a besoin de savoir où chercher et ce que les choses veulent dire au moment où il agit. C’est de la sémantique opérationnelle, pas du nettoyage analytique.
Trois, le dogme inverse l’ordre causal. Vous découvrez quelles données comptent en faisant tourner les agents. Cycle : agent en production, friction identifiée, nettoyage ciblé, meilleure performance. A l’inverse, dix-huit mois de nettoyage avant est la meilleure façon de polir ce dont personne n’aura besoin.
Quatre, et c’est le plus politique, le dogme arrange beaucoup de monde. Les CDO qui ont passé cinq ans à construire leur plateforme, les ESN qui vendent du data engineering, les éditeurs de data warehouse : tous ont intérêt à allonger la phase amont. Pas du complot : un agenda à noter quand on entend la phrase.
Ce qui reste vrai, et qu’il faut concéder honnêtement. Le référentiel client / produit / commande doit être réglé : si « client » veut dire trois choses dans trois systèmes, l’agent fera des bêtises au premier remboursement. Tout ce que l’agent écrit doit être gouverné : lire des données sales, un LLM s’en sort ; écrire dans un système aux règles métier mal documentées, c’est là que ça casse. Et en domaine régulé (santé, finance, données personnelles) « data clean d’abord » devient « data gouvernée d’abord » : l’AI Act et les régulations sectorielles imposent traçabilité et qualité d’entrée.
La règle pratique : ne nettoyez pas tout votre patrimoine data avant de lancer un agent. Pilotez un agent sur un périmètre choisi, repérez ce qui frotte, et nettoyez là où ça frotte.
Ce que ça change pour votre organisation
Un robot n’a pas les mêmes besoins qu’un exosquelette. Concrètement, l’agentique exige quatre choses de plus :
- des données en temps réel, pas un batch de la nuit dernière ;
- un accès en lecture et écriture dans les systèmes opérationnels ;
- une vérité sémantique fiable : l’agent doit savoir ce que « client », « commande » ou « stock » veut dire, sans ambiguïté ;
- une gouvernance des actions : qui valide quoi, jusqu’où, avec quel filet.
Prenez les deux premières. Un data warehouse est construit sur les données d’hier : il aspire et centralise pendant la nuit, pour qu’on analyse le passé le lendemain. Très bien pour un tableau de bord. Inutilisable pour un agent conversationnel par exemple, pour un retailer, un agent personal shopper qui doit voir le panier maintenant et pouvoir agir dessus : ajouter un article, rembourser, modifier une commande, en temps réel.
C’est là le vrai changement de paradigme. L’agentique met sous tension un plan opérationnel que la décennie data warehouse a négligé. La stack data ne se simplifie pas, elle se dédouble. Avant, le DWH servait une question : l’analyse du passé. Avec l’agentique, deux plans coexistent désormais :
- Un plan opérationnel, où vivent les agents : événements temps réel, APIs transactionnelles, bus d’événements, feature stores online, lecture et écriture dans les systèmes de référence (ERP, CRM, OMS). C’est là que la boucle agent, décision, action se ferme.
- Un plan analytique et sémantique, où vit toujours le DWH : référentiel, historique, métriques, définitions partagées, observabilité métier. C’est là que vous pilotez la flotte d’agents : KPI, dérive, audit, conformité.
Ces deux plans communiquent (CDC, reverse ETL, metric layer), mais ne se confondent pas. Le DWH ne perd pas son rôle ; il n’est simplement plus tout le rôle.
C’est aussi un déplacement des modèles eux-mêmes. Pendant dix ans, les data scientists ont construit des modèles de ML en bout de chaîne, derrière le DWH et toutes ses étapes de raffinage. Les LLM, eux, vont vivre beaucoup plus à la périphérie : intégrés aux outils métiers, branchés sur les systèmes opérationnels, dans l’expérience utilisateur en temps réel. Le centre de gravité de l’IA se déplace du fond du SI vers son interface avec le réel.
Au passage, l’agentique ne tue pas le DWH. Elle révèle la dette technique opérationnelle que le DWH masquait en aspirant tout chaque nuit. Beaucoup d’entreprises découvrent qu’elles ont sous-investi pendant dix ans sur leur couche transactionnelle et événementielle au profit du data warehouse : des Snowflake magnifiques posés sur des SI opérationnels en plat de spaghetti, sans APIs propres, sans event stream, sans système de référence clair pour « client » ou « commande ». L’agentique met cette dette à la lumière.
Et au sommet de tout ça, il faut un humain responsable. Quand ça dérive, et ça dérive, il faut quelqu’un qui réponde. Souvenez-vous de Sonos : une application ratée déployée en 2025, un fiasco, et un CEO qui saute. Une IA, elle, peut vous envoyer dans le mur sans la moindre conséquence pour elle ; elle vous dira « désolé » en souriant et recommencera. L’humain, lui, porte un risque réputationnel et une exposition personnelle. Cette apparente faiblesse joue pour vous : c’est précisément ce qui vous permet de déléguer à un agent, et de dormir la nuit.
Reste à se méfier d’un chiffre. Les cinq heures de la courbe METR, c’est le seuil de réussite à 50 % : une fois sur deux. En production, on exige 80 %, et bien au-delà, et là, les horizons s’effondrent. « Réussir une fois sur deux » n’a jamais fait tourner une supply chain, bouclé une clôture comptable ni tenu un parcours client. L’écart entre la capacité brute et la fiabilité exploitable, c’est exactement le terrain de la gouvernance, de la supervision, de l’humain responsable. La capacité file devant ; le déploiement fiable reste un travail d’organisation, le seul que personne ne pourra jamais déléguer à un agent.
C’est la lecture du last mile (Lakhani, Spataro & Stave, HBR 2026) : le composant qui bloque n’est presque jamais le modèle, c’est la donnée, la gouvernance, l’adoption. Ici, le maillon en retard, c’est une architecture pensée pour analyser le passé alors qu’on lui demande d’agir au présent. C’est un changement d’architecture et d’organisation, pas un changement d’outil. Et c’est précisément pour ça qu’il est si souvent sous-estimé comme « projet technique » alors que c’est une transformation organisationnelle.
Le régulateur, lui, l’a déjà compris. L’EU AI Act, en vigueur depuis 2025, impose pour les systèmes à haut risque un système de gestion des risques continu (Art. 9) et une supervision humaine effective (Art. 14), y compris la capacité de surseoir, de renverser une décision et d’actionner un « stop button ». Et la règle est limpide : plus l’autonomie est élevée, plus les exigences montent. Un agent agissant sur un domaine régulé (crédit, RH, santé) sera quasi systématiquement classé « haut risque ». Deloitte (2026) a analysé plus de 350 risques propres aux agents autonomes (MIT AI Risk Database) et identifie quatre dimensions à gouverner : l’exécution orientée résultat, l’adaptation de la logique de décision, la portée et la mémoire, l’interconnectivité.
Ce déplacement bouscule la chaîne de responsabilités. Voici, ligne à ligne, ce qui bouge :
| Rôle avant | Rôle avec les agents | |
|---|---|---|
| Métiers / Ops | Exécutent la tâche | Définissent l’intention, supervisent, arbitrent les cas limites ; tenus pour responsables de la performance |
| Data org | Centralisent la donnée au repos, DWH, reporting | Garantissent la donnée en mouvement, le temps réel, la lecture/écriture, et la vérité sémantique |
| CoE IA | Développent dashboards et modèles ML en bout de chaîne, en aval du DWH | Déploient des modèles directement intégrés aux systèmes opérationnels, au plus près de l’usage |
| DSI / Platform | Hébergent et sécurisent les systèmes | Garantissent robustesse, observabilité et maîtrise des coûts d’une flotte d’agents en production, chaque agent est un nouvel endpoint à gouverner |
L’exosquelette amplifiait vos gestes sans rien changer à votre organisation. Le robot, lui, vous oblige à repenser qui décide, qui exécute, et qui répond. Une fois que la machine est lancée, il est trop tard pour réfléchir à ces questions. C’est là que se joue la vraie transformation, et c’est le seul travail qu’aucun agent ne fera à votre place.
Article suivant (4/7) : Les compétences de l’ère agentique : ce que vos équipes vont devoir apprendre (et désapprendre).
Vous lisez la série « Agents IA en entreprise ». Pour recevoir les prochains articles : abonnez-vous à la newsletter sur Substack et suivez Florent Cattaneo sur LinkedIn.
Nous contacter
Entreprises, Institutions, Talents : contactez-nous ici ou directement via nos pages Linkedin